在本博客中,什么叫淘客,我们将了解如何在SAP Data Intelligence中使用机器学习跟踪服务。
要了解有关SAP Data Intelligence的更多信息,请参阅此处。
我们为什么需要跟踪服务?众所周知,建立机器学习模型是一个涉及多个步骤的迭代过程。大多数情况下,广西大数据,数据科学家在Jupyter笔记本上运行多个实验,通过调整基础模型、优化模型参数、调整超参数、更改采样方法、尝试不同的库或版本等,然后使用print语句(大多数情况下)比较这些经过训练的模型。当模型和参数的数量增加时,这会变得混乱和难以管理。因此,数据科学家无法重现实验,无法跟踪模型的性能,也无法找出过去哪些有效,哪些无效。
SAP数据智能中的跟踪服务正试图为上述问题提供解决方案。它为数据科学家配置、捕获、组织、再现和可视化机器学习实验提供了一个框架。
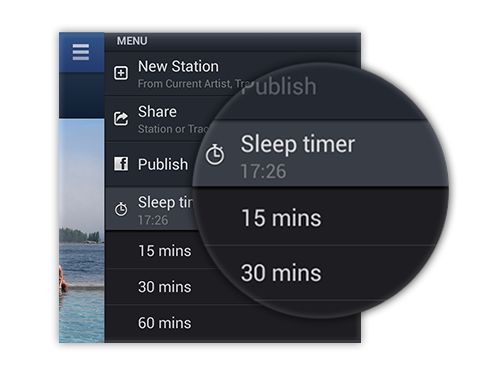
通过跟踪,数据科学家可以定义需要捕获的内容,软件企业的认定,如模型参数、模型度量、模型超参数、随机种子等其他配置,然后还可以查看捕获的信息从ML Scenario Manager中的Metric Explorer(请参见下面的预览)。
您还可以在此处的视频中看到Metric Explorer正在运行,在此处的视频中看到Tracking SDK。
因此,让我们开始吧。
启动SAP Data Intelligence并从启动板选择ML Scenario Manager。
在Scenario Manager中,单击+创建新方案
在"创建方案"对话框中提供一些名称和业务问题详细信息,然后单击"创建"。
方案已创建,用户将被重新定向到"详细信息"页面。
在"笔记本"部分下,单击+创建新笔记本。
在"创建笔记本"对话框中提供笔记本的名称和说明,物联网技术与应用,然后单击"创建"。
创建Jupyter笔记本,并将用户重新定向到笔记本页面以选择内核。
在笔记本中选择Python 3
一次,使用以下命令从DI SDK导入跟踪:
跟踪的主要实体是运行。
运行是机器学习实验的实例,包括一次迭代的度量和参数以及相关的标记。
建议的方法是在ML实验代码的开头使用start_Run()和end_Run()
通过start_run()初始化运行时,自动记录场景详细信息、源详细信息、开始时间等元数据信息
允许使用run Collection对运行进行逻辑分组。当用户初始化运行时,他们可以(可选)指定要在其中关联此运行的运行集合。如果未指定,系统将为每个源创建一个默认运行集合。
使用log\U metric功能记录度量。它需要参数名称和值,其中值必须是数字。
您可以使用log\U metrics函数传递要捕获的度量项列表。列表中的每一项都是一个字典,其参数与log\u metric函数相同。
使用log\u parameters函数记录参数。它需要参数名称和值。每个参数的类型必须是字符串(如果传递了另一个类型,则会自动转换为字符串)。
设置标签功能可用于设置当前运行下的标签。标记是与运行关联的用户定义属性。每个标记都是一个键(字符串)-值(字符串)对。
get_runs函数获取包含度量、参数、标记等的运行对象。它需要一个或多个参数scenario、scenario\u version、pipeline、execution、notebook和run.
SDK为run创建一个ID,并在调用start\u run()时将其作为run对象返回。您可以使用此对象检索此运行中记录的度量和参数。
标记也可以用于筛选运行。
如果用户希望在结束\u run()后记录某些度量,可以调用log \u metric函数,并将关联的运行对象作为附加参数。
结束,跟踪SDK可以用来捕获和组织实验。下图反映了运行、运行集合和各种跟踪对象的概念。
注意:它不代表技术基础设施。
示例代码如下:
实验结束后,您可以通过Metric Explorer查看运行并可视化度量。
或者,您也可以查询运行以及Tracking SDK中的度量,并使用python库在笔记本中绘制它们。
对于作为上述示例跟踪代码的一部分捕获的度量,返利折扣,您可以使用下面的示例脚本