背景
在我们之前的博客中,我们已经成功地创建了一个自定义连接器,并且能够使用钩子格式化Trello dashboard的响应。我觉得还是少了些什么。每次我都要运行我的资源来获取数据。如果我们想从Trello那里得到实时或接近实时的数据呢。我可以看到两种选择,一种是从Trello中提取数据,另一种是将Trello中的数据推送到我们打开的连接器中。以固定的间隔从Trello拉取数据称为轮询,当Trello将数据推送到连接器时,这是通过webhooks完成的。因此,让我们讨论一下如何使用轮询方法获得接近实时的数据。
在高级轮询中解密轮询
就像在后台安排的作业,它以固定的间隔获取给定URL的数据。它就像我们在web开发中使用的cron,用于调度某些脚本,大数据产品,请阅读此处了解有关轮询的更多详细信息。
使用轮询的第一个也是最基本的要求是,响应应创建或更新日期和时间戳,在我们的情况下,我们确实有。我们在上一篇博客中丢失的格式化响应中也添加了日期和时间。
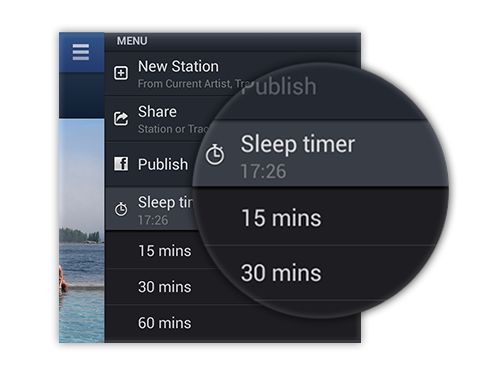
下一步是打开我们的自定义连接器->转到设置选项卡->打开事件->选择轮询。
下一步我们需要指定需要拉取数据的条件和间隔。由于我们的trelloapi提供程序没有通过where子句提供查询过滤器,我们将把created和updated字段留空。如果支持它,您需要做的就是将字段名映射到这里和URL的where子句中。由于我们没有任何过滤选项,个人如何建站,我们将在接下来的几个步骤中通过自定义javascript代码进行过滤。
我们还拥有一个轮询级别的javascript控制台,以丰富我们接收到的数据。这与我们在上一篇博客中看到的内容类似。我们这里有可用的事件对象,如下所示,我们添加了事件类型和对象类型细节,什么叫云服务,并调用了done方法。
现在,因为我们每次都得到没有任何过滤器的所有板。我们将通过增强我们的钩子代码来做到这一点,我们将检查在过去5分钟内是否有任何更改,我们只需要Trello板的信息。因此,响应现在不仅被格式化,大数据前景,而且被过滤。
最终输出
基本测试可以通过首先创建自定义连接器实例,然后手动执行端点来完成,如下所示。我在几分钟前更改了存储库,因此只返回该存储库。
但是由于我们已经通过轮询实现了它,所以让我们创建一个新实例,并激活轮询选项。每5分钟触发一次。我将对存储库进行更改,它将在第一次运行时获取该记录,在以后的运行中该记录应为空。所有API调用等的执行日志可以在activities页签中找到(由于轮询发现了它,以后会详细讨论),大数据怎么样,如下所示
下一步是什么?
从现在起,我们已经讨论了轮询,下一步是探索webhooks如何适合定制连接器的故事情节。在本系列的下一部分将详细讨论自动获取此文件的主要用途。请随时提供您的反馈意见,并向所有人开放。