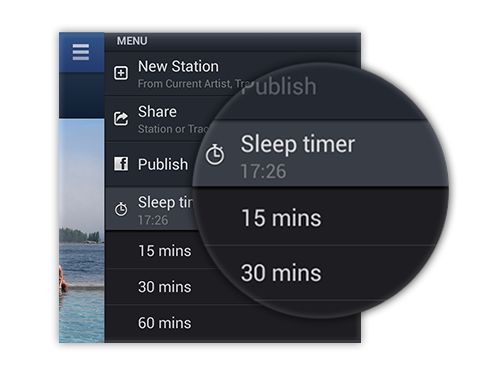
专利保护独特的想法和知识产权。专利美化是公司、专利局和学术界常用的一种分析方法,51返利,人工智能包含哪些方面,用于更好地了解大量专利的潜在技术覆盖范围,其中由于时间或成本限制,云服务器特价,手动审查(即实际阅读专利)不可行。幸运的是,专利包含丰富的信息,包括元数据(审查员提供的分类代码、引文、日期和有关专利申请人的信息)、图像和数千字的描述性文本,由于机器学习模型提高了从业者分析所有这些数据的能力,专利美化技术得到了改进。在谷歌的全球专利团队中,我们开发了一种新的专利美化方法,它在谷歌云上使用Python和BigQuery,使您能够轻松访问专利数据并生成自动化的景观。
在开始进行专利美化时,需要了解一些重要的概念。使用这些信息源的机器学习(ML)造景方法通常分为两类:
本篇文章的重点是监督的专利造景,这种方法往往影响更大,并且在各个行业中普遍使用,例如:
尽管景观美化方法历来依赖于关键字搜索和应用于元数据的布尔逻辑,但监督景观美化方法越来越多地使用先进的ML技术从专利的实际全文中提取含义,其中包含的描述性信息远比元数据丰富。尽管最近取得了这些进展,但大多数受监督的专利美化方法至少面临以下挑战之一:
我们开发的新专利美化方法满足了上述所有常见缺点。这种方法使用Colab(Python)和GCP(BigQuery)来提供以下好处:
请继续阅读,以获得该方法的高级概述和代码片段。完整的代码可以在这里找到,并且可以为您自己的ML和BigQuery项目重用和修改。最后,如果您需要介绍Google公共专利数据集,可以在这里找到一个很好的概述。选择一个种子集和一个专利代表生成一个景观首先需要一个种子集作为搜索的起点。为了产生高质量的搜索,输入专利本身应该密切相关。更密切相关的种子集往往会产生围绕同一技术覆盖范围更紧密聚集的景观,而一组完全随机的专利可能会产生嘈杂和更不确定的结果。
输入集可能跨越合作专利代码(CPC)、技术、受让人、发明人等。,或者是一份涵盖某些已知技术领域的专利清单。在本演练中,使用术语(词)查找种子集。在Google专利公共数据集中,有一个"top terms"字段可用于"Google\u Patents"中的所有专利_研究、出版"桌子。该字段包含专利中使用的10个最重要的术语。术语可以是单克(如"气动弹性"、"基因分型"或"发动机")或双克(如"电路"、"背景噪声"或"导热系数")。
选择种子集后,您接下来将需要一个适合通过算法的专利表示。与其使用专利的整个文本或专利的离散特征,不如为每个专利使用嵌入。嵌入是通过某种模型输入数据的学习表示,通常采用神经网络结构。它们通过将输入的最重要特征映射到连续数向量来降低输入集的维数。使用嵌入的一个好处是能够计算它们之间的距离,因为向量之间存在多个距离度量。
您可以在BigQuery中找到一组专利嵌入。专利嵌入是使用一个机器学习模型构建的,淘客返利app,该模型从文本中预测专利的CPC代码。因此,网建站,学习到的嵌入是64个连续数字的向量,用于编码专利文本中的信息。然后可以计算嵌入之间的距离,并将其用作两项专利之间的相似性度量。
在下面的示例查询(在BigQuery中执行)中,我们随机选择了2005年1月1日之后授予的一组美国专利(并收集了它们的嵌入),顶部术语为"神经网络"