聚类模型对数据进行分组,使得同一组中的对象与其他组中的对象具有相似的特征(因此它们是"同质的")。根据2017年KDnuggets民意测验,聚类是第二流行的机器学习方法,k-均值算法无疑是最流行的算法之一,它的应用范围非常广泛,例如寻找相似客户群、细分市场、优化沟通策略和提高营销效率、定位产品或选择测试市场相对接近的,因此数据点之间的"距离"的概念很重要。而且,大多数k-均值算法要求预先指定簇的数目,称为"k",这是该算法的最大缺点之一。
然而,淘客购物,该算法简单易懂,基本上是一个优化问题:找到k个聚类中心,将对象分配到最近的聚类中心,使聚类的平方距离(从每个对象到其中心的距离)之和最小,从而使聚类中的对象尽可能接近因此,它们的特征尽可能相似。
该算法在简单的二维表示中很容易遵循,企业应用系统,但在现实世界中,你将使用更多的维度。这意味着,不是用两元素向量(x1,x2)来描述观测,您将使用n元素向量(x1,x2,…,xn)描述的观察值,其中每个元素都是您选择用来创建聚类组的不同输入变量。
您将从数据集中的观察值开始。您将仔细准备数据,必要的数据争用过程将在本博客后面介绍。
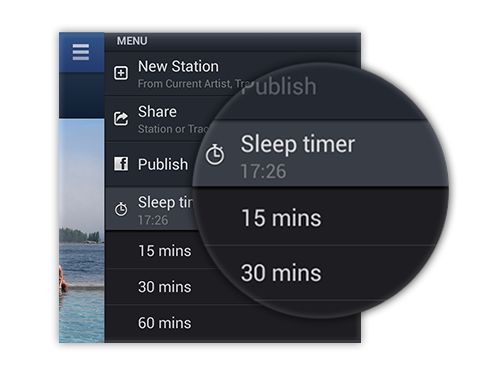
您需要选择要查找的集群数量。k-means的一些实现将使用您指定的一系列集群来构建集群模型,并保留被认为是最佳集群数量的模型。但是,您的第一个决定是要指定簇的数量或范围:
步骤1–为每个簇指定一个簇中心。
假设您决定尝试3簇解决方案,因此在随机观测位置选择3个簇中心(+):
步骤2:算法计算每个观测到每个簇中心的距离(通常使用欧几里德直线距离:
第3步:分配聚类"标签",以便将每个观测值分配到最近的聚类中心:
第4步:算法计算每个聚类中每个观测值的平均值(如每个聚类的"group by"SQL语句,然后计算平均值),然后该平均值成为每个集群的新集群中心:
步骤5:重复步骤2到4,直到集群成员不再改变,模型收敛到最终解决方案:
如您所见,这项技术需要大量的试验和错误(比如当你测试不同的k值时),要找到最佳的解决方案需要一些初步的分析,多次运行,以及对不同的解决方案的评估?你所要达到的是一个解决方案,其中一个簇中的观测值有一个自然的关联,所以它们彼此更相似,而不是另一个簇中的观测值。要做到这一点,你需要将关联的概念转化为某种相似程度的数值度量。
方法是将所有维度转化为数值,以便将观测值视为空间中的点。如果两点在几何意义上接近,然后你假设它们是相似的。
有两个问题:
正确格式化你的数据
因此,主要的挑战之一是准备好数据,使其采用正确的格式,以便k-means算法正确工作。你应该遵循以下几个步骤:
确定缺失的值,并填充或删除这些值缺少值的记录。识别异常值,或者删除它们,或者以某种方式转换值,什么是大数据,使它们不再具有影响力。确定任何有偏差的维度,并创建转换来调整数据分布,大数据行业前景,使其具有正态分布。如果有任何分类维度,则需要创建"虚拟"(析取)版本,其中每个变量的每个类别都成为一个新的数值变量,值为0或1。识别并删除任何"冗余"尺寸。冗余维度是由于解释维度之间的相关性(称为"多重共线性")而产生的,一种方法是分析相关矩阵,识别任何具有高相关性的维度对,然后移除其中一个维度,以便从模型中移除任何冗余。对所有解释维度进行缩放,使它们处于相同的缩放比例,并且可以进行合理的比较。你可以使用最小-最大标准化或z-分数来实现这一点。
所有这些步骤都有很多变化,导致成千上万的文章描述了不同的方法。但是,您会发现,对于大量的维度,需要花费大量的时间和精力来正确准备数据,以便在这个相对简单的算法中使用。
自动聚类算法方法
我建议您检查的一种方法是中提供的自动聚类算法SAP Predictive Analytics。它使用k-means,但有一点扭曲。它可以使用目标变量(因此它是一种"监督"聚类),并且它具有自动数据编码,数据更新,因此所有的数据准备步骤都为您完成,节省您所有的时间和精力!